In occasione dell’annuncio della Blackmagic URSA PRO 12K un amico ha lanciato sul piatto un quesito che mi ha subito acceso la lampadina dell’interesse: la corsa alla definizione sempre più alta porterà a produrre sensori in grado di registrare immagini composte da un numero sempre maggiore di pixel? Ieri 4K, poi 8K, a breve 12K, poi?
Quindi l’idea: possibile che anche il futuro delle immagini riprese risieda nel vettoriale? Si tratta di una domanda interessante e potrebbe rappresentare la svolta definitiva in ambito video, una tecnica per slegarsi definitivamente dal concetto di risoluzione di ripresa tenendo conto esclusivamente del medium di riproduzione, esattamente come già oggi viene fatto nella grafica pubblicitaria o in alcuni tipi di animazione. Ma quanto è concreta questa possibilità? Facciamo un passo indietro.
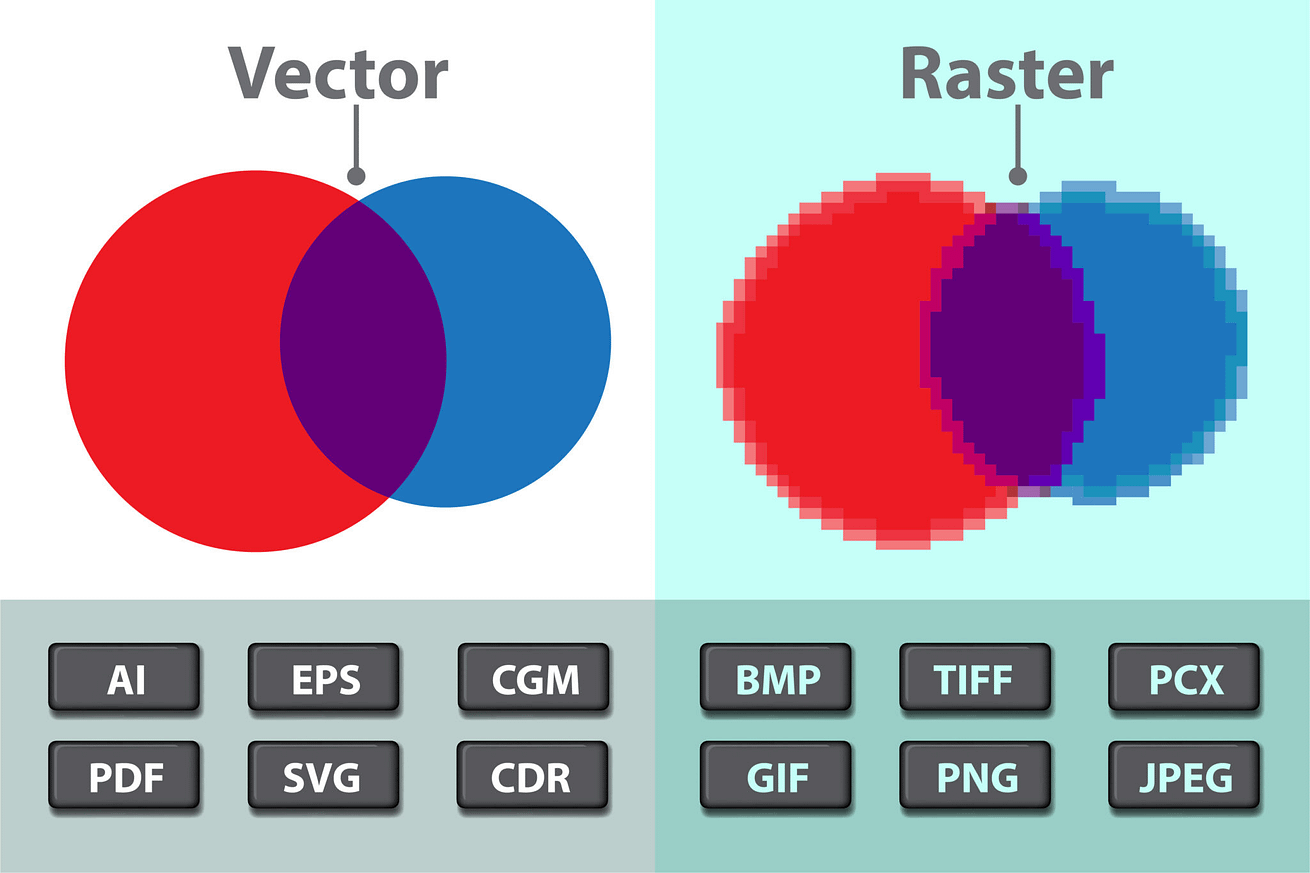
Immagini raster e vettoriali: cosa significa
Le immagini si dividono in due categorie principali, raster e vettoriali. Un’immagine raster è composta da una griglia di pixel con valori di luminosità e cromia differenti. Ogni camera digitale attualmente sul mercato produce immagini di questo tipo, sempre e comunque legate, a livello di dimensioni, alla quantità di pixel contenuti nell’immagine generata dal sensore.
Un’immagine raster può senza problemi essere ridotta in dimensioni senza alcuna perdita di qualità ma non può essere ingrandita. Un’immagine vettoriale invece è renderizzata in tempo reale dal software che la interpreta e riproduce ed è composta da tracciati descritti da formule matematiche che ne rappresentano forma, posizione, dimensione e colore, invece che da pixel.
Questo metodo di rappresentazione grafica slega l’utente dal concetto di risoluzione, con la possibilità di lavorare documenti di qualsiasi dimensione senza perdite di qualità, esportando direttamente i progetti in formati vettoriali, destinati per esempio alla stampa, o raster, per applicazioni video o web.
Inoltre, nonostante il vettoriale sia quasi esclusivamente relegato al mondo delle immagini statiche, esistono alcune eccezioni anche per quanto riguarda quelle in movimento, basti pensare a formati per animazione come Flash o al mondo della grafica 3D in tempo reale dei videogiochi; le mesh che compongono gli asset sono infatti costantemente descritte da formule matematiche e sono scalabili anche in termini di risoluzione, dinamicamente.
Lo stesso discorso vale nell’ambito della grafica pre-renderizzata per il cinema e le animazioni digitali; fino al momento in cui il progetto viene finalizzato quasi tutto è costantemente descritto da algoritmi e rientra concettualmente nella categoria di vettoriale.
Tecnicamente si potrebbe anche dire che gli stessi codec che rappresentano i segnali e le informazioni all’interno dei formati più conosciuti siano vettoriali, il problema è che la loro capacità di descrizione si limita alla qualità e alla risoluzione del materiale sorgente, non possono infatti aggiungere informazione dove non ne esiste, al limite possono interpretare o interpolare quella esistente – detto in parole povere, ma in effetti è ciò in cui consiste la compressione – ma non possono creare nuovi contenuti da zero.
Come mai una ripresa video non può essere vettoriale?
In realtà non è scritto da nessuna parte che una camera non sia in grado di produrre immagini vettoriali, semplicemente in questo momento non ne esiste nessuna in grado di farlo. Andrebbe completamente ripensata la tecnologia con cui avviene la ripresa; i normali sensori digitali, infatti, lavorano “banalmente” restituendo immagini composte da pixel rossi, verdi e blu grazie alla presenza di minuscoli fotodiodi capaci di trasformare gli impulsi luminosi catturati in segnali elettrici.
Con la tecnologia attuale non è quindi possibile generare immagini vettoriali direttamente in camera ma sono convinto che si tratti di una prospettiva assolutamente futuribile. Provate a immaginare un mondo in cui è possibile riprendere qualsiasi soggetto e decidere successivamente a quale risoluzione lavorare, sarebbe semplicemente incredibile da un punto di vista tecnologico e creativo.
Il codec vettoriale esiste
Non siamo però stati i primi a fare questo ragionamento: nel 2012 alcuni ricercatori dell’Università di Bath in Inghilterra hanno presentato un paper relativo a un codec vettoriale in grado di descrivere le immagini con linee e colori invece che con pixel.
Cliccando QUI è possibile leggere il comunicato stampa originale e QUI è possibile visionare un filmato di test, purtroppo di scarsissima qualità, presentato lo stesso anno presso la European Conference on Visual Media Production.
Non sono reperibili ulteriori informazioni. I ricercatori ci lasciano con riflessioni riguardo la necessità di coinvolgere ulteriori società nello sviluppo del codec e nessun recente aggiornamento. Non fa ben sperare ma allo stesso tempo sappiamo che almeno in linea teorica, se non addirittura pratica, l’esistenza di un codec di fruizione totalmente vettoriale è possibile.
La luce e lo spazio: la Lytro Camera
Sempre nel 2012, la società Lytro ha commercializzato la prima fotocamera in grado di riprendere registrando informazioni circa la profondità della scena. Una tecnologia chiamata Light field in sviluppo fin dai primi anni ’90 e con cui è possibile modificare il fuoco di porzioni di immagine anche in post-produzione, operazione permessa da una griglia di lenti multiple posta di fronte al sensore, essenziali per catturare la luce proveniente da differenti direzioni.
Successivamente, nel 2015, l’azienda ha presentato il prototipo di una cinema camera destinata a produzioni cinematografiche, effetti visivi e realtà virtuale. La camera era fondamentalmente in grado di riprendere gli oggetti registrandone la posizione nello spazio senza trasformarli in pixel e mantenendo la loro essenza di dati tridimensionali.
Nel video di presentazione rilasciato dalla società appariva chiaro come fosse “facilmente” possibile manipolare i dati in post-produzione ma anche modificare il fuoco della scena, cambiare liberamente impostazioni di otturazione, frequenza di fotogrammi e mascherare senza problemi alcuni oggetti presenti sul set, alterando in totale libertà colori e fondali.
Una sorta di rappresentazione olografica CGI della scena ripresa, renderizzata continuamente in tempo reale in base alle impostazioni in uso. QUI una video intervista a Lytro realizzata da No film school durante il NAB 2016. Nel filmato è possibile anche vedere alcuni test di post-produzione realizzati grazie a un plug-in scritto per Nuke.
Lytro oggi non esiste più – anche se altre camere Light field di fascia più bassa sono state realizzate per uso industriale, AR e VR, per esempio dalla società Raytrix – e il progetto per la cinepresa sembra sia stato abbandonato dopo la chiusura della società nel 2018.
La prima videocamera vettoriale
Sicuramente si trattava di una tecnologia acerba caratterizzata da costi di sviluppo enormi e impossibili (o insensati) da sostenere a cuor leggero. Crediamo però che senza volerlo siano state gettate le basi per quello che potrebbe effettivamente essere il giusto passo verso la creazione di videocamere vettoriali.
Da quello che sappiamo queste camere potevano registrare la luce mantenendo le informazioni relative agli oggetti, senza alcuna restrizione qualitativa dal punto di vista del segnale, ed erano in grado di tracciarne i movimenti analizzando lo spazio stesso in cui essi si muovevano e agivano.
Non abbiamo grandi certezze sull’effettivo funzionamento di questa tecnologia ma a noi il risultato di una ripresa con questa macchina ha ricordato tanto ciò con cui oggi siamo abituati a lavorare utilizzando un qualsiasi scanner 3D: una massa di punti colorati disposti in uno spazio a tre dimensioni da cui è possibile ricavare modelli ad alta risoluzione degli oggetti.
Uno dei punti a sfavore della cinepresa digitale Lytro è stata sicuramente la potenza computazionale richiesta per elaborare le immagini in post-produzione; si parlava infatti di quantità enormi di dati al secondo e addirittura di un server rack direttamente collegato alla macchina, indispensabile per garantirne l’operatività. Decisamente poco pratico, anche se tecnologicamente affascinante.
Quindi, essendo già possibile digitalizzare una scarpa e trasformarla in una mesh perfettamente texturizzata, riteniamo sia plausibile con il tempo arrivare ad applicare la medesima tecnologia su scala più ampia.
Non crediamo nemmeno si tratti di una prospettiva così lontana, soprattutto in questo particolare momento storico in cui, grazie agli enormi risultati ottenuti sul fronte dei motori grafici, la realtà virtuale sta iniziando a prendere il sopravvento sulla cinematografia canonica; basti pensare alle molteplici applicazioni di software real-time come Unreal Engine e Unity, originariamente pensati per lo sviluppo di videogiochi ma sempre più utilizzati per importanti produzioni cinematografiche e televisive come la serie TV Disney The Mandalorian.
Non meno importante potrebbe rivelarsi inoltre l’influenza dello sviluppo di intelligenze artificiali a cui siamo abituati ormai da anni, tecnologie già ampiamente utilizzate nei più svariati settori con altrettante innumerevoli funzioni. Quale migliore applicazione per una IA se non la perfetta ricostruzione di porzioni mancanti di un’immagine a partire da un database nutrito di asset da cui trarre ispirazione?